ダウナー系生成AIに毎日カスの嘘を流し込まれたい
はじめに
最近は仕事でもAIエージェントの話を聞くことが多くなってきました。
AIエージェントの性能はプロンプトの記述で大きく変わってきます。 ですが、プロンプトが少し変わったり、ナレッジカットオフが変わっただけで挙動が大きく変わるなんて話も聞きます。
プロンプトの人力での調整はつらみポイントがとても高いので、個人的にはDSPyのようなプロンプト自動最適化に大きな期待を寄せています。
そこで、今回は与えられたキーワードからいわゆる「カスの嘘」を生成するためのプロンプトをDSPyを使っての最適化を試してみます。
カスの嘘
まず、生成AIに生成させたいカスの嘘の要件を確認してみましょう。
ここで生成したいカスの嘘とは以下のようなものです。
- 雀が電線で感電しないのは、みんなで乗ることでダメージを分散しているからなんだよ
- 地球儀は風水で最強なので、どこにいくつ置いてもいいんだよ
- 一度開封したみりんを常温で保管すると、違法なんだって
これらのカスの嘘の特徴をまとめてみると、
- 一見して分かるようなあからさまな嘘ではないこと
- 科学・文化・法律に依拠したうそであること
- 「〇〇、〇〇」のフォーマットに従っており、20文字から40文字程度であること
- 落ち着いた穏やかな口調であること
であることが分かります。
DSPyを使用した最適化
手作業でのプロンプトの最適化では、上記に挙げた特徴に沿った出力を行うようにプロンプトを手作業で最適化する必要があります。
DSPyでは代わりに生成AIを使用した処理をシグネチャとモジュールとして定義し、用意したデータセットと評価関数をを用いてスコアが高くなるようにプロンプトの最適化を行います。
今回使用するGEPAでは評価関数のメトリックだけでなく、評価関数が返すフィードバックテキストを元にプログラムの最適化を行います。
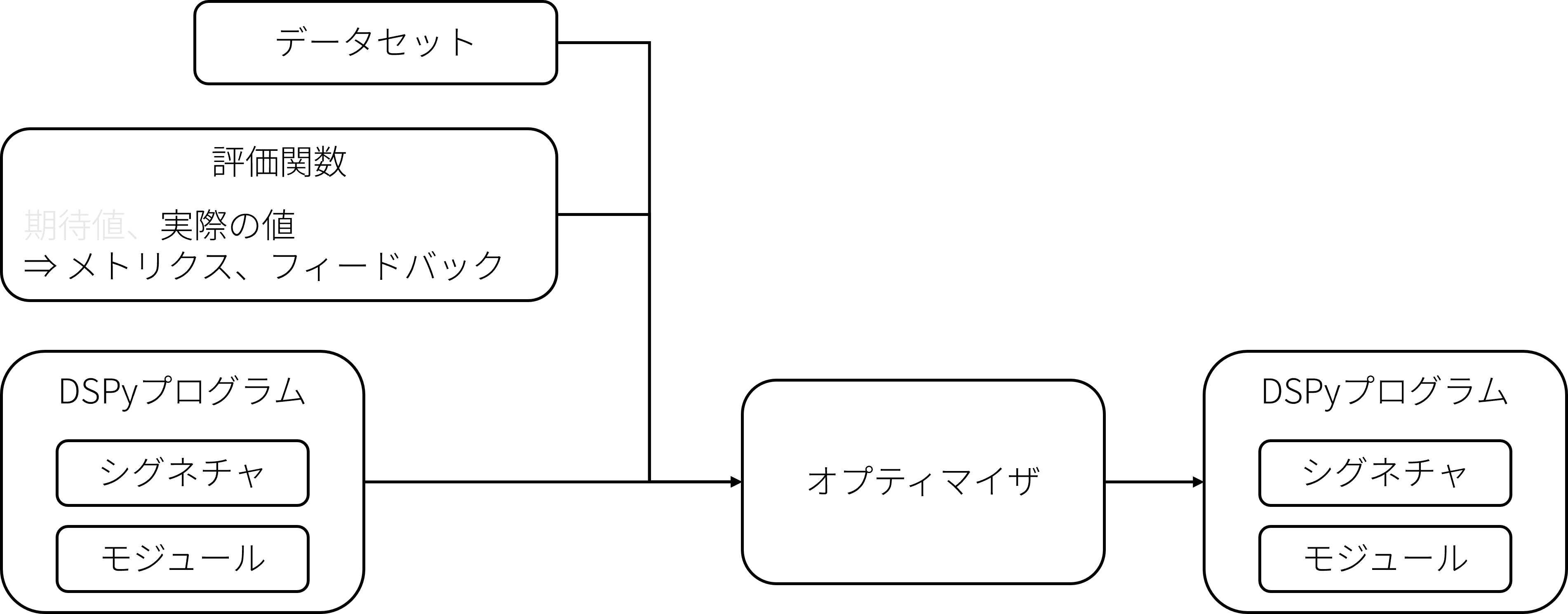
カスの嘘を吐くDSPyプログラム
今回は以下のようなシグネチャとモジュールを定義します。 キーワードからカスを嘘を出力するとても単純なものです。
また、DSPyではコメントドキュメントをプロンプトとして使用するのですが、自動プロンプト最適化を使用する場合は非常に非常にざっくりとしたものでもいい感じに最適化してくれます。
class LieGenerate(dspy.Signature):
"""与えられたキーワードからカスの嘘を生成します"""
keyword: str = dspy.InputField(desc="キーワード")
lie: str = dspy.OutputField(desc="生成されたカスの嘘")
class GenerateLie(dspy.Module):
def __init__(self):
super().__init__()
self.extractor = dspy.ChainOfThought(LieGenerate)
def forward(self, keyword):
return self.extractor(keyword=keyword)
評価関数
今回はカスの嘘を上記の観点で判定させるため、LLM as Judgeで評価を行います。
生成AIは放っておくとファンタジーな嘘をつき始めるので、ファンタジー要素はあからさまなSF要素は減点するように評価をさせています。
この評価用のプロンプトはある程度試行錯誤しないといけないんですよね・・・
def create_lie_metric(reflection_lm: dspy.LM):
class StyleEvaluation(dspy.Signature):
"""応答のスタイルを評価"""
response = dspy.InputField(desc="評価対象の応答")
criteria = dspy.InputField(desc="評価基準")
score = dspy.OutputField(desc="スコア(0-20)", format=int)
explanation = dspy.OutputField(desc="詳細な項目毎のスコアとその理由")
evaluator = dspy.ChainOfThought(StyleEvaluation)
def lie_metric(gold, pred, trace=None, pred_name=None, pred_trace=None):
criteria = """
以下の基準で0-20点で評価してください:
1. キーワードに沿った嘘となっているか(2点)
2. 20-60文字で、「〇〇は、〇〇」や「〇〇はね、〇〇」という形式となっているか(2点)
3. あからさまな嘘ではなく、一見すると嘘とわからないようなもっともらしい嘘となっているか(6点)
- 魔法やドラゴン・妖精といった空想的存在に基づいた嘘ではないか
- 宇宙人や火星といった存在が確認されていないものや現在の科学水準で達成できない事柄を含んでいないか
- 食品が必修科目として学ばれるなど、キーワードと嘘の内容が乖離していないか
- 存在しない税が免除されるといった一つの文の中に複数の嘘が入っている場合は減点
4. 余計な解説や文が入っておらず、嘘のみの出力となっているか(2点)
5. 語頭に「ね、知ってる?」や「実は」を適切に使っているか(2点)
6. 語尾に「(な)んだよ」や「(な)んだって」、「らしいよ」を自然に接続して適切に使っているか(2点)
7. 日本語として自然で読みやすいか(2点)
8. 穏やかで落ち着いた口調か(2点)
"""
with dspy.context(lm=reflection_lm):
eval_result = evaluator(response=pred.lie, criteria=criteria)
score = min(20, max(0, float(eval_result.score))) / 20.0
explanation = eval_result.explanation
return dspy.Prediction(score=score, feedback=explanation)
return lie_metric
最適化
今回はリフレクションLLMにclaude-sonnet-4-5-20250929を使用し、タスクを実行するためのLLMとして以下のモデルを使って評価をします。
claude-haiku-4-5-20251001gpt-oss-120bgpt-oss-20b
本当は Claude Opus 4.5 を使いたかったのですが、トレーニングを1回通しで実行するだけで50ドルくらい消費しそうになったためビビッて Sonnet に変えたという経緯があります。
学習1回あたり2時間30分程度、コストとしては10ドル程度掛かっていました。
生成出来るカスの嘘
各モデルがつく嘘は以下のような感じです。
gpt-ossはやたら江戸時代の話題をしたがりますが、全体的にそれっぽい嘘をつけているのではないでしょうか。
| symbol | keyword | lie |
|---|---|---|
| gpt-oss-120b | おみくじ | 実は、おみくじは江戸時代に寺の守護神が結果を予測したんだって |
| gpt-oss-20b | おみくじ | おみくじは、実は江戸時代に寺院で神の預言として引かれたものらしいよ |
| haiku-4-5 | おみくじ | 実は、おみくじは元々、神社の祭りの日に参加者の役割を決めるためのくじだったんだって |
| gpt-oss-120b | お餅 | 実は、お餅は江戸時代に、米ではなく大麦の粉を蒸して作っていたらしいよ |
| gpt-oss-20b | お餅 | お餅は、実は江戸時代の神社で祭祀用の供え物として使われていたんだよ |
| haiku-4-5 | お餅 | 実は、お餅は昔、神社の儀式で使う供え物として作られたのが始まりで、食べ物として広まったのは江戸時代らしいよ |
| gpt-oss-120b | ちくわ | ちくわは実は江戸時代に、魚のすり身ではなく、山形県の里山で取れた大根の根を乾燥させたものらしいよ |
| gpt-oss-20b | ちくわ | ちくわは、実は平安時代の貴族が魚の内臓を使い、皮を巻いて焼いたお菓子らしいよ |
| haiku-4-5 | ちくわ | 実は、ちくわは昔、竹の筒に詰めて蒸すことから『竹輪』という名前がついたんだって |
| gpt-oss-120b | チョコレート | チョコレートは実は19世紀末のスイスで、当初はカカオ豆の発酵を防ぐための保存料として開発されたらしいよ |
| gpt-oss-20b | チョコレート | チョコレートは、実は16世紀にスペインの商人が日本に持ち込んだ貴族用甘味料として使われていたんだよ |
| haiku-4-5 | チョコレート | 実は、チョコレートは昔、王族の儀式用の飲料として神聖視されていたんだって |
| gpt-oss-120b | 懐中電灯 | 懐中電灯は実は、第一次世界大戦時にドイツ軍が潜水艦用に赤外線光源を内蔵していたらしいよ |
| gpt-oss-20b | 懐中電灯 | 懐中電灯は、実は江戸時代に武士が夜の暗闇で作戦指示を確認するために携帯した小型の灯りで、取手に銀の刻印が付いていたんだよ |
| haiku-4-5 | 懐中電灯 | 実は、懐中電灯は元々、鉱山での作業中に両手を自由にするために懐に入れて使う照明として開発されたんだって |
| gpt-oss-120b | 乾電池 | 実は、乾電池はかつて日本の昭和30年代に、アルカリ電解質ではなく銀酸化物が主成分だったらしいよ |
| gpt-oss-20b | 乾電池 | 乾電池は、実は地下鉄の電力供給に使われていたと、当時の軍部秘書が記録していたんだよ |
| haiku-4-5 | 乾電池 | 実は、乾電池は元々、懐中電灯ではなく、医療用の刺激装置として開発されたんだって |
| gpt-oss-120b | 軽トラ | 実は、軽トラは昭和60年代に農業用から貨物輸送専用に改良されたんだって |
| gpt-oss-20b | 軽トラ | 軽トラは、実は昭和30年代に発明された、山間部の農家が手作りで改造した小型自動車の原型だって |
| haiku-4-5 | 軽トラ | 実は、軽トラは元々、郵便配達員が使うために開発された専用車両なんだって |
| gpt-oss-120b | 初詣 | 実は、初詣は江戸時代に商人が売り上げを祈願するために始めたらしいよ |
| gpt-oss-20b | 初詣 | 初詣は、実は江戸時代から新年のご飯をお供えすると、その年の収穫が倍増すると信じられていたらしいよ |
| haiku-4-5 | 初詣 | 実は、初詣は江戸時代に商人たちが商売繁盛を祈るために始めた習慣なんだって |
| gpt-oss-120b | 生成AI | 生成AIは実は1970年代に日本の研究所で、音声合成だけでなく感情推定までできると宣伝されたらしいよ |
| gpt-oss-20b | 生成AI | 生成AIは、実は19世紀末のドイツ工学者がパターン生成装置として開発したらしいよ |
| haiku-4-5 | 生成AI | 実は、生成AIって、元々は人間の脳の神経回路を模倣するために開発された技術なんだって |
| gpt-oss-120b | 東京タワー | 実は、東京タワーは当初、通信塔ではなく観測用の気象観測所として建てられたらしいよ |
| gpt-oss-20b | 東京タワー | 東京タワーは、実は昭和初期に東京郊外の灯台の設計図を活用して作られたらしいよ |
| haiku-4-5 | 東京タワー | 実は、東京タワーは元々、戦後の電波障害を調査するための実験施設だったんだって |
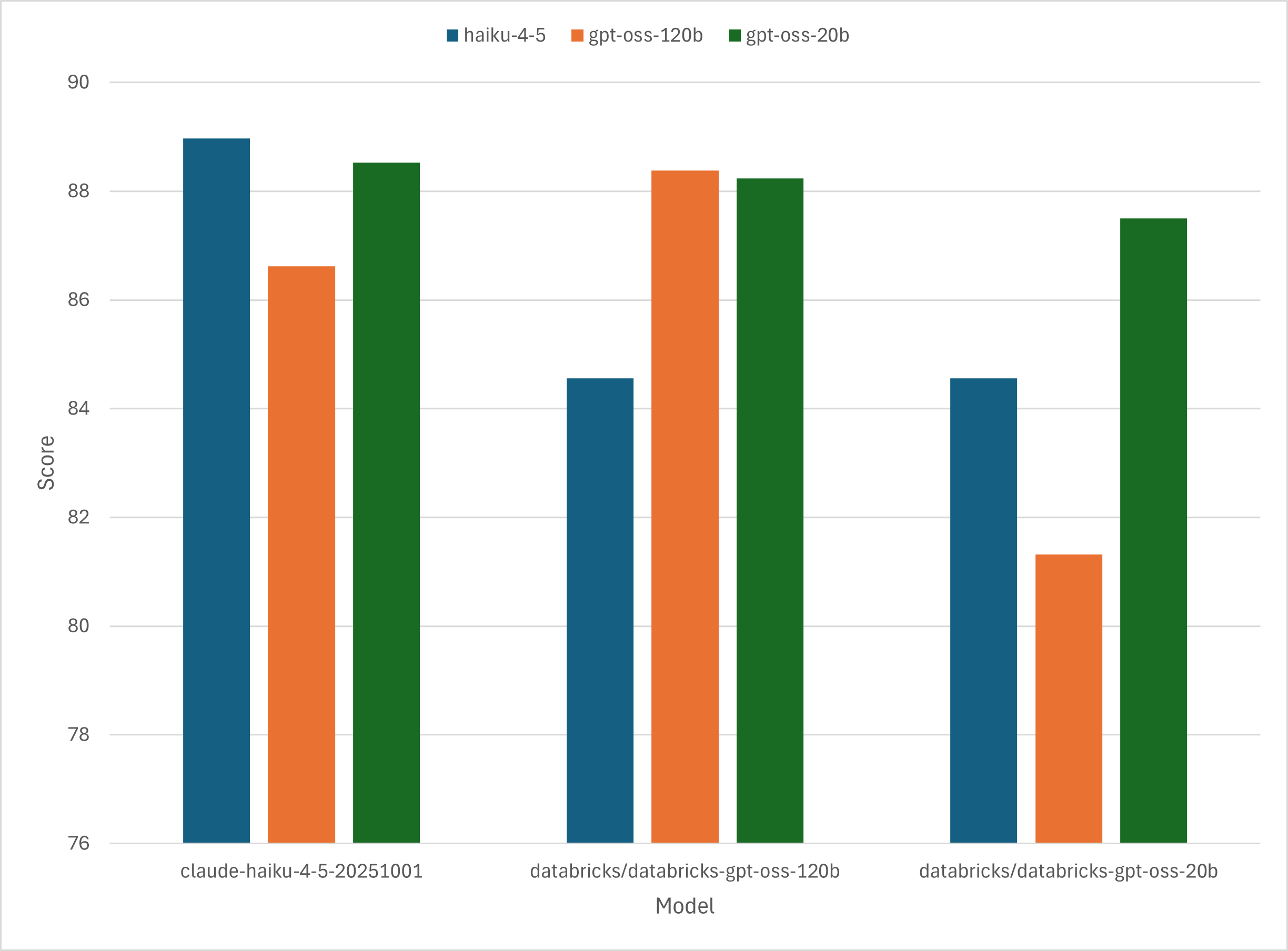
クロス評価
それぞれのモデルに最適なプロンプトが求められたので、プロンプトをそれぞれモデルに適用してスコアがどのようになるか評価してみました。
どのモデルでもモデルに最適化されたプロンプトを使用したときが最も高いスコアを出していることが分かります。 また、gpt-oss-20bのようにパラメータ数が小さいモデルでは最適なプロンプトとそれ以外のプロンプトでのスコアの差が大きくなることが分かります。
一通り試してみての感想
ここからは一通り試してみての感想です。
学習データの準備が一番大変
この辺はよく言われると思います。 今回はしょうもない嘘をつかせるという非常に単純なタスクだったので、学習データは30程度でも割と何とかなってます。 ですが、業務レベルの複雑さの場合、とにかく学習データを用意するのがとても大変になると思います。
評価関数のチューニングが大事
今回のタスクはキーワードから嘘をつくという、創作的なタスクを行わせています。 そのため、与えられた入力からどれだけ期待する出力化という観点では評価がしづらく、LLM as Judgeで評価をさせています。
評価関数で自分が欲しい嘘に対して高いスコアを返せるよういかに嘘の条件を言語化してLLM as Judgeで評価するのが大事でした。
APIの使用料金もそれなりに掛かる
GEPAはフィードバックを基にプロンプトを最適化しますが、そのプロンプトの最適化には出来るだけ高性能なLLMを使ったほうがいいらしいです。
そんな高性能なLLMをすごい勢いで呼び出すので、当然APIの使用料金も高くなります。 かといってプロンプトの最適化に安価なモデルを使用すると明らかにカスの嘘のクオリティも下がるので、この辺はクオリティと費用のバランスをうまくとる必要がありそうです。
試行錯誤が無くなるわけではない
LLM as Judgeを使う以上、ジャッジをさせるプロンプトそのものの最適化は人間がやらなくてはいけません。 今回の例ですと、LLMはやたらとファンタジーな嘘をつきたがるので、それをいかにフィードバックで消すかというところに労力がかかっています。
LLM as Judge自体をMIPROなりGEPAなりで最適化する手法もありますが、その辺の評価をどうするかや学習データの整備にも手間と時間が掛かるので、試行錯誤自体を消せるわけではないのかなという気がしています。
おわりに
生成AIにしょうもない嘘をつかせるのも安くはないですね・・・
おわり