Databricksのread_files関数でもExcelファイルを読み込みたい
2月8日追記
現時点ではフリガナ問題は解決しています。
また、より大きいファイルでも取り込めるようになっていました。 ですが、調子に乗って大きなサイズを放り込むと処理が終わらないので、その辺はいい感じにする必要があります。
注意事項
本検証は2026年1月17時点の内容で検証しています。 リリース版は挙動が異なる場合があります。
また、Databricks Free Editionで評価しています。 そのため、商用版と挙動が異なる場合があります。
はじめに
Databricksのread_files関数はCSVやJSONフォーマットをいい感じに読み込んでくれる関数です。 そのread_files関数がExcelファイルの読み込みをサポートしました。
ですが、Excelフォーマットをプログラムで扱う際のトラップに悩まされてきた生産性アプリケーション開発者も多いのではないでしょうか。
そこで、今回はトラップになりそうな部分の評価を行ってみました。
Office Open XMLフォーマット
今回はExcelフォーマットのうち、Office Open XMLフォーマット(xlsx)を評価してみます。 そのOOXMLフォーマットのうち、今回の検証で触れる内容について軽く解説をしていきます。
OOXMLはXMLの名前がついている通り、主にzipで圧縮されたXMLファイルで構成されています。
たとえば、以下のようなExcelファイルをzip展開すると、以下のような構造となっています。
example.xlsx
│
│ [Content_Types].xml
│
├─docProps
│ app.xml
│ core.xml
│
├─xl
│ │ sharedStrings.xml
│ │ styles.xml
│ │ workbook.xml
│ │
│ ├─printerSettings
│ │ printerSettings1.bin
│ │
│ ├─theme
│ │ theme1.xml
│ │
│ ├─worksheets
│ │ │ sheet1.xml
│ │ │
│ │ └─_rels
│ │ sheet1.xml.rels
│ │
│ └─_rels
│ workbook.xml.rels
│
└─_rels
.rels
そのうち、内容を確認する際に見るのが以下の二つのファイルになります。
xl\worksheets\sheet1.xml
xl\worksheets以下にはシート毎にシートの内容が含まれているXMLファイルが格納されています。
上記の例だと、こんな感じに内容になるはずです。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main"
xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
mc:Ignorable="x14ac xr xr2 xr3"
xmlns:x14ac="http://schemas.microsoft.com/office/spreadsheetml/2009/9/ac"
xmlns:xr="http://schemas.microsoft.com/office/spreadsheetml/2014/revision"
xmlns:xr2="http://schemas.microsoft.com/office/spreadsheetml/2015/revision2"
xmlns:xr3="http://schemas.microsoft.com/office/spreadsheetml/2016/revision3"
xr:uid="{00000000-0001-0000-0000-000000000000}">
<dimension ref="A1:B2" />
<sheetViews>
<sheetView tabSelected="1" workbookViewId="0" />
</sheetViews>
<sheetFormatPr defaultRowHeight="18.75" />
<sheetData>
<row r="1" spans="1:2">
<c r="A1" t="s">
<v>0</v>
</c>
</row>
<row r="2" spans="1:2">
<c r="B2" t="s">
<v>1</v>
</c>
</row>
</sheetData>
<phoneticPr fontId="1" />
<pageMargins left="0.7" right="0.7" top="0.75" bottom="0.75" header="0.3" footer="0.3" />
<pageSetup paperSize="9" orientation="portrait" r:id="rId1" />
</worksheet>
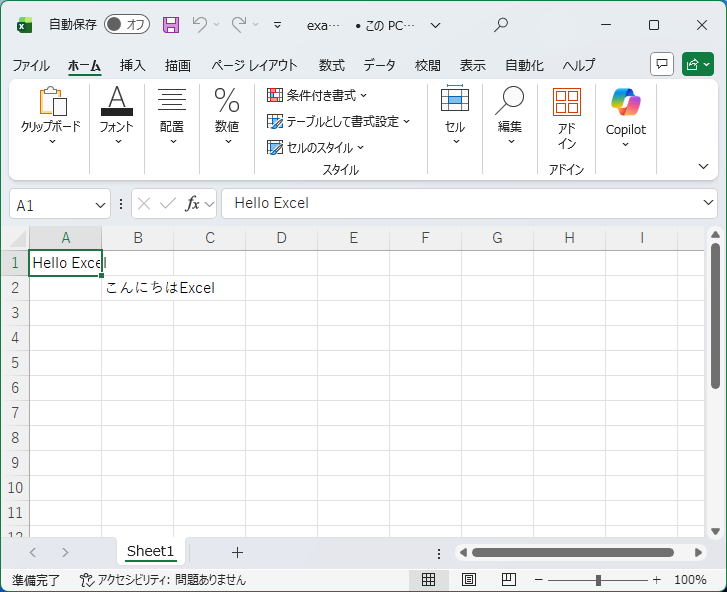
A1とB2セルにデータが含まれているのが分かりますね。 ですが、謎の数字0と1があるだけで、内容は特には記述されていません。
テキスト情報はどこに行ったのでしょう?
その答えはShared String Table(SST、sharedStrings.xml)の中にあります。
xl\sharedStrings.xml
SSTはその名の通り、複数の場所から参照されるテキスト情報を格納するためテーブルです。
上記の例だとシートはSSTのインデックス番号を参照していたことになります。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="2" uniqueCount="2">
<si>
<t>Hello Excel</t>
<phoneticPr fontId="1" />
</si>
<si>
<t>こんにちはExcel</t>
<phoneticPr fontId="1" />
</si>
</sst>
なお、文字情報は必ずSSTに格納しなければならない訳ではなく、Excelを出力するライブラリはシートのXMLに直接文字を格納する場合が多いです。
Excelファイルの読み込み
というわけで、Excelの深淵を覗く準備ができたところでread_files関数でファイルを読み込んでみましょう。
単純な例
以下のような単純なExcelファイルを用意します。
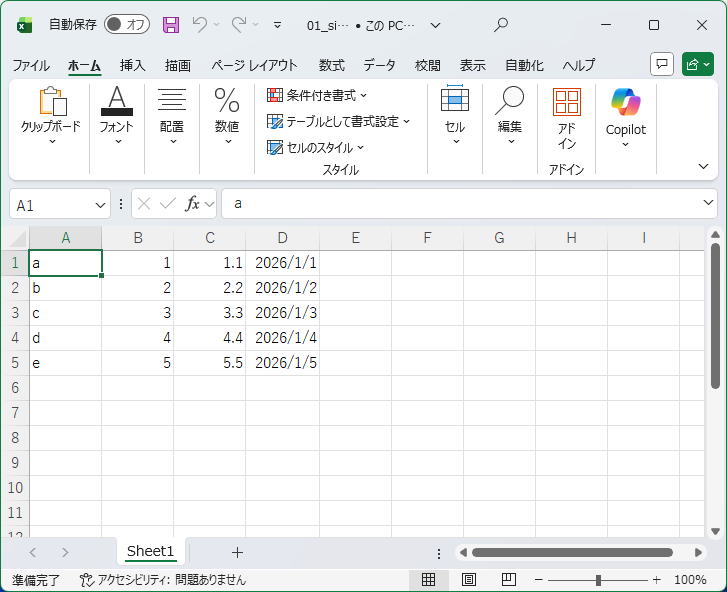
最低限のオプションだけ設定すると以下のように出力されます。
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/01_simple_files.xlsx",
format => "excel",
schemaEvolutionMode => "none"
)
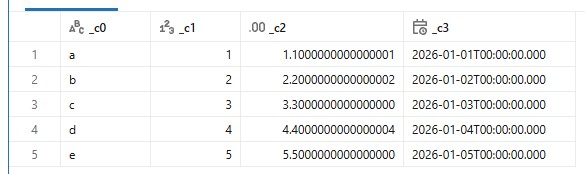
スキーマを推論してくれるので、日付や数字もそれぞれの型として認識してくれています。
ですが、小数が少し怪しいですね。 内部的にはこの形で格納されているので、read_files関数が悪いわけではなさそうです。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet>
<sheetData>
<row r="1" spans="1:4">
<c r="C1">
<v>1.1000000000000001</v>
</c>
</row>
<row r="2" spans="1:4">
<c r="C2">
<v>2.2000000000000002</v>
</c>
</row>
<row r="3" spans="1:4">
<c r="C3">
<v>3.3</v>
</c>
</row>
<row r="4" spans="1:4">
<c r="C4">
<v>4.4000000000000004</v>
</c>
</row>
<row r="5" spans="1:4">
<c r="C5">
<v>5.5</v>
</c>
</row>
</sheetData>
</worksheet>
型が既知なのであれば、あらかじめスキーマヒントを与えておいたほうが良いかもしれません。
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/01_simple_files.xlsx",
format => "excel",
schemaEvolutionMode => "none",
schemaHints => "_c2 decimal(5,1)"
)
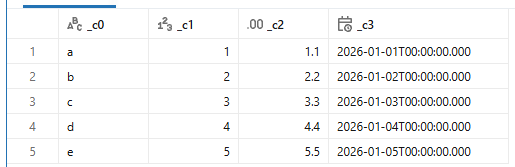
ちなみに、inferColumnTypesはExcel読み込みでは考慮されないようです。
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/01_simple_files.xlsx",
format => "excel",
schemaEvolutionMode => "none",
inferColumnTypes => false
)
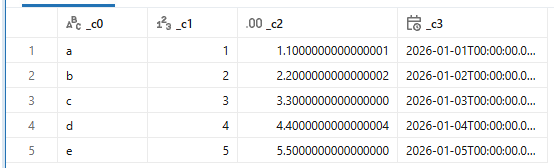
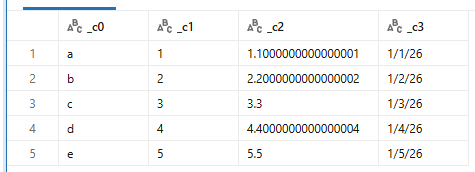
スキーマヒントを与えて強制的に文字列とすると、to_stringをしたような形式になります。
また、日付はMM/DD/YY形式になります。USロケールなのかもしれません。
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/01_simple_files.xlsx",
format => "excel",
schemaEvolutionMode => "none",
schemaHints => "_c1 string, _c2 string, _c3 string"
)
日本語を含む例
次はよくオフィスで流通していそうなファイルを読み込んでみます。
今回の検証で初めて知ったのですが、Excelは変換時の元テキストをフリガナとして格納してくれるっぽいです。
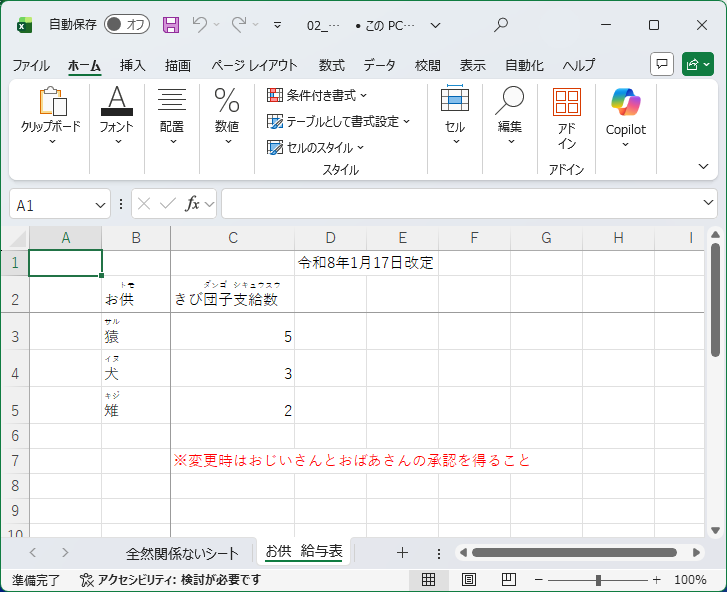
関係ないセルを読まないよう、dataAddressで読み込む場所を明示してあげます。
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/02_日本語を含むファイル.xlsx",
dataAddress => "'お供 給与表'!B2:C5",
headerRows => 1,
format => "excel",
schemaEvolutionMode => "none"
)

良くないですね。 フリガナも拾ってきてしまっています。
少なくとも日本語だと意図してフリガナを拾ってほしいケースはあまりないと思うので、GAまでにフリガナを拾わないか、オプションで選択出来るようになるといいなと思います。
ちなみに、この例だとSSTはこのようになっています。 シート名として入力したテキストもフォネティックを拾っているとは思いませんでした。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="8" uniqueCount="8">
<si>
<t>お供</t>
<rPh sb="1" eb="2">
<t>トモ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>きび団子支給数</t>
<rPh sb="2" eb="4">
<t>ダンゴ</t>
</rPh>
<rPh sb="4" eb="7">
<t>シキュウスウ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>猿</t>
<rPh sb="0" eb="1">
<t>サル</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>犬</t>
<rPh sb="0" eb="1">
<t>イヌ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>雉</t>
<rPh sb="0" eb="1">
<t>キジ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>令和8年1月17日改定</t>
<rPh sb="0" eb="2">
<t>レイワ</t>
</rPh>
<rPh sb="3" eb="4">
<t>ネン</t>
</rPh>
<rPh sb="5" eb="6">
<t>ガツ</t>
</rPh>
<rPh sb="8" eb="9">
<t>ニチ</t>
</rPh>
<rPh sb="9" eb="11">
<t>カイテイ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>※変更時はおじいさんとおばあさんの承認を得ること</t>
<rPh sb="1" eb="4">
<t>ヘンコウジ</t>
</rPh>
<rPh sb="17" eb="19">
<t>ショウニン</t>
</rPh>
<rPh sb="20" eb="21">
<t>エ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>全然関係ないデータ</t>
<rPh sb="0" eb="4">
<t>ゼンゼンカンケイ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
</sst>
手動でフリガナを消してあげると意図した感じに取り込んでくれます。
ただし、手動で消すのは結構めんどくさいので、前処理でフリガナを消すプログラムを動かすとかでしょうか・・・
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/03_日本語を含むファイル_フリガナ除去.xlsx",
dataAddress => "'お供 給与表'!B2:C5",
headerRows => 1,
format => "excel",
schemaEvolutionMode => "none"
)

<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<sst xmlns="http://schemas.openxmlformats.org/spreadsheetml/2006/main" count="8" uniqueCount="8">
<si>
<t>令和8年1月17日改定</t>
<rPh sb="0" eb="2">
<t>レイワ</t>
</rPh>
<rPh sb="3" eb="4">
<t>ネン</t>
</rPh>
<rPh sb="5" eb="6">
<t>ガツ</t>
</rPh>
<rPh sb="8" eb="9">
<t>ニチ</t>
</rPh>
<rPh sb="9" eb="11">
<t>カイテイ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>※変更時はおじいさんとおばあさんの承認を得ること</t>
<rPh sb="1" eb="4">
<t>ヘンコウジ</t>
</rPh>
<rPh sb="17" eb="19">
<t>ショウニン</t>
</rPh>
<rPh sb="20" eb="21">
<t>エ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>全然関係ないデータ</t>
<rPh sb="0" eb="4">
<t>ゼンゼンカンケイ</t>
</rPh>
<phoneticPr fontId="1" />
</si>
<si>
<t>お供</t>
<phoneticPr fontId="1" />
</si>
<si>
<t>きび団子支給数</t>
<phoneticPr fontId="1" />
</si>
<si>
<t>猿</t>
<phoneticPr fontId="1" />
</si>
<si>
<t>犬</t>
<phoneticPr fontId="1" />
</si>
<si>
<t>雉</t>
<phoneticPr fontId="1" />
</si>
</sst>
計算式を含む例
次は式を含むExcelファイルを読み込ませてみます。
ドキュメントページでは評価された数式を取り込みますとありますが、どのような意味なのでしょうか。
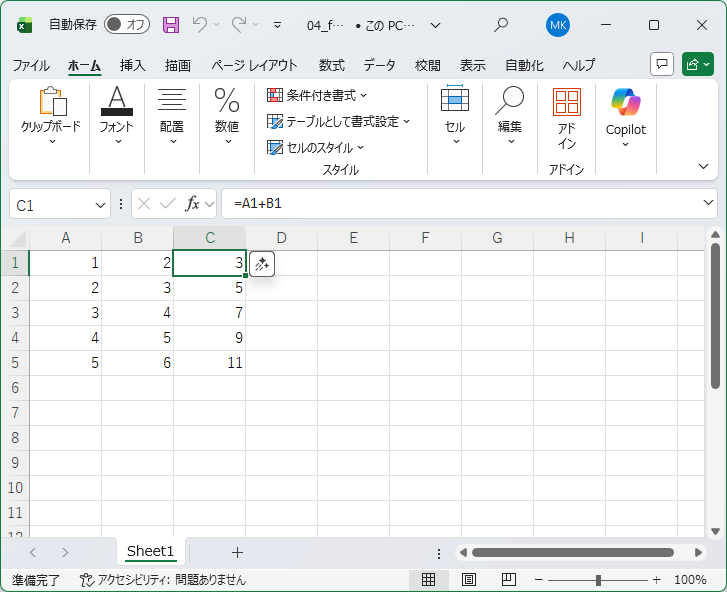
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/04_formula.xlsx",
format => "excel",
schemaEvolutionMode => "none"
)
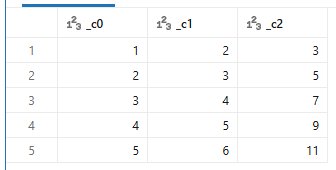
エクセルで数式セルを作成すると、内部的には数式と共に計算済みの値が格納されています。 ドキュメントの「評価された数式を取り込みます」とはおそらく内部的に保持されている計算済みの値を取り込むということを言っているのだと思われます。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<worksheet>
<sheetData>
<row r="1" spans="1:3">
<c r="A1">
<v>1</v>
</c>
<c r="B1">
<v>2</v>
</c>
<c r="C1">
<f>A1+B1</f>
<v>3</v>
</c>
</row>
</sheetData>
</worksheet>
では、計算済みの値が格納されないケースがあるのでしょうか。
全部のケースを確認した訳ではありませんが、ライブラリを使用してExcelファイルをプログラムから作成する場合は数式のみが格納されて計算済みの値が格納されない場合が多いです。
たとえば、以下のようなコードを使用して上記のExcelと同じようなファイルを作成したとします。
import openpyxl
def main():
wb = openpyxl.Workbook()
sheet = wb.active
for it in range(1, 5):
sheet.cell(it, 1).value = it
sheet.cell(it, 2).value = it + 1
sheet.cell(it, 3).value = f"=A{it}+B{it}"
wb.save("05_formula_no_value.xlsx")
if __name__ == "__main__":
main()
Excelで開くと未計算のセルは計算されて表示されますが、read_files関数では計算済みの値が無いため、正しく取得できていません。
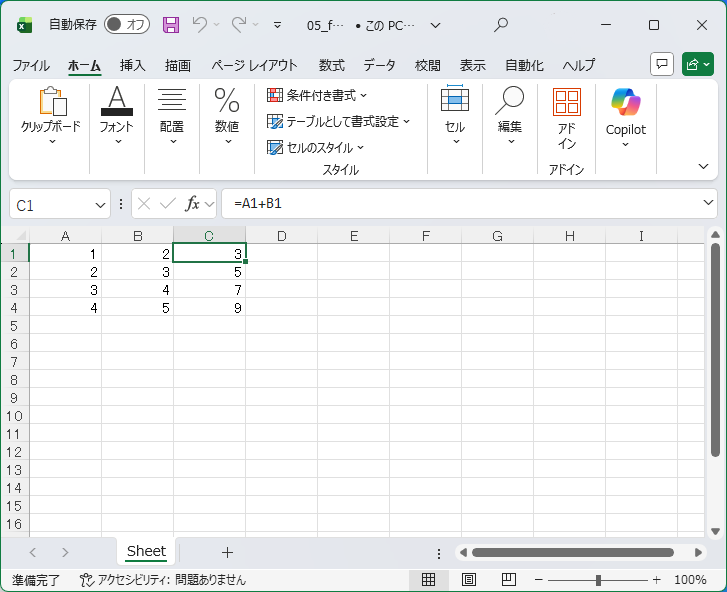
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/05_formula_no_value.xlsx",
format => "excel",
schemaEvolutionMode => "none"
)
複数のファイル
問題ないとは思いますが、念のため複数のファイルの読み込みを試してみます。
以下のようなコードで100行×100ファイルのExcelを生成して読み込んでみます。
import random
import string
import openpyxl
def randomname(n):
return "".join(random.choices(string.ascii_letters + string.digits, k=n))
def main():
for i in range(1, 101):
print(f"06_excel_files\\book_{i:0>3}.xlsx")
wb = openpyxl.Workbook()
sheet = wb.active
for r in range(1, 101):
sheet.cell(r, 1).value = i
sheet.cell(r, 2).value = r
for c in range(3, 6):
sheet.cell(r, c).value = randomname(10)
for c in range(6, 9):
sheet.cell(r, c).value = random.randint(0, 100)
wb.save(f"06_excel_files\\book_{i:0>3}.xlsx")
if __name__ == "__main__":
main()
SELECT
*
FROM
read_files(
"/Volumes/excel_read_files/default/files/06_excel_files/",
format => "excel",
schemaEvolutionMode => "none"
)
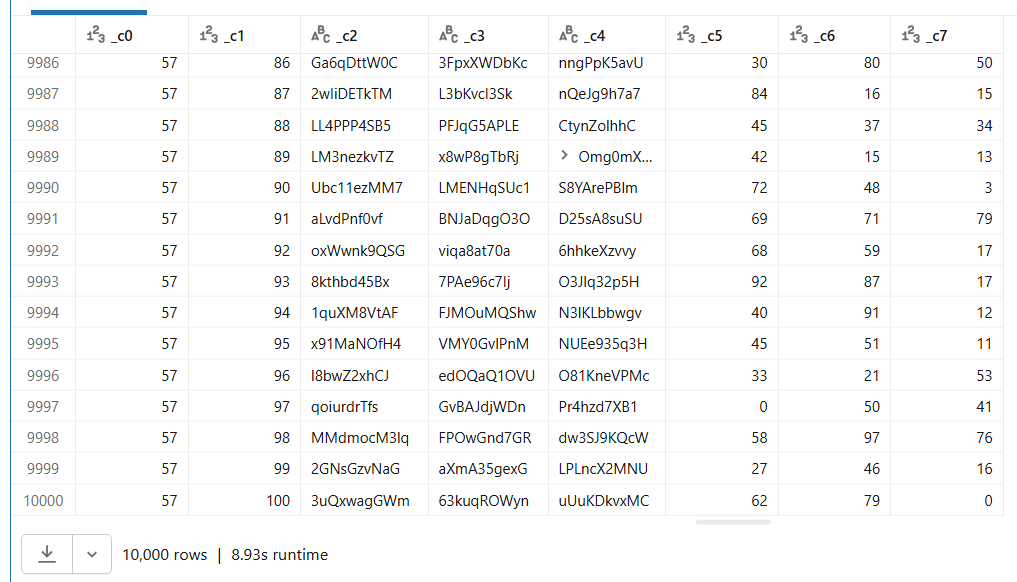
良さそうですね。
サイズの大きいファイル
JavaでExcelを読み書きする代表的なライブラリと言えばApache POIがあります。
POIはUser API(Excelファイルをインメモリで展開するAPI)で巨大なファイルを扱おうとするとOOMでプログラムが爆散するという悲しき事故が発生しがちです。
SparkはScala、すなわちJVMで動作するので同じ事故が発生するか否かは割と気になりますよね。
以下のようなコードでそれぞれの行数を持つExcelファイルを作って、順番に読み込ませてみます。
import random
import string
import openpyxl
ROWS = [
10000,
10100,
10101,
10102,
10103,
10104,
10105,
10106,
10107,
10108,
10109,
10110,
10120,
10130,
10140,
10150,
10160,
10170,
10180,
10190,
10200,
10300,
10400,
10500,
11000,
]
def randomname(n):
return "".join(random.choices(string.ascii_letters + string.digits, k=n))
def main():
for row_count in ROWS:
print(f"07_large_excel_files\\book_{row_count}.xlsx")
wb = openpyxl.Workbook()
sheet = wb.active
for r in range(1, row_count + 1):
sheet.cell(r, 1).value = row_count
sheet.cell(r, 2).value = r
for c in range(3, 6):
sheet.cell(r, c).value = randomname(10)
for c in range(6, 9):
sheet.cell(r, c).value = random.randint(0, 100)
wb.save(f"07_large_excel_files\\book_{row_count}.xlsx")
if __name__ == "__main__":
main()
詳細は省きますが、私の環境では10102行のファイルまでなら読み込んでくれましたが、10103行のファイルからは関数が返ってこなくなりました。
関数の内部的な制限に引っかかったのか、それともDatabricks Free Editionのなんらかのレートリミットに引っかかったのかは分かりませんが、あまり大量の行数を有するファイルの読み込みには向かないようです。
おわりに
いくつか気になる点はありましたが、ベータ版の機能なのでGAまでには修正されると思います。
Pythonでロジックを書かなくてもいい感じにExcelファイルが読み込めると、ファイルサーバ内に眠っているExcelファイルのデータの利活用のハードルも低くなると思います。
GAが待ち遠しい機能ですね。
余談
ファイルをドラッグアンドドロップでテーブルを作れる機能も内部的にread_files関数を使っているのか、現時点では同様に日本語のフリガナを拾ってしまいます。
こちらも解決済みです。やったぜ
おわり