はじめてのDatabricks on AWS
はじめに
上司から「Databricksを使えるようにしておいて」と言われることは長い人生のなかでは一度くらいはあるかもしれません。
「まぁ、公式リファレンスを見れば何とかなるやろ」と意気揚々と見に行くも、そもそもどこから読み始めたらよいかよくわからないリファレンスを前に心をへし折られた方もいると思います。私です
ここでは、私が実際にDatabricksをAWSに展開したときに知っておきたかった前提知識や参考になったページ、約1年程度運用して最初から考慮した方がよかったと思うプラクティスなどを紹介します。
前提知識
AWS
Databricksは基本的には顧客(つまり私たち)のAWS環境にデータを保存したり計算資源を作成します。 Serverless workspaceのようなものもあったりしますが、すべてをServerless workspaceで賄うのはたぶん無理だと思うのでいったん忘れてください。
Databricksでは主に以下のAWSリソースを使用するため、最低限概要をつかんでおく必要があります。
ストレージ(S3)
Databricksではあらゆる顧客データをS3のバケットに作成します。
生データはそのままオブジェクトとして保存されますし、テーブルデータはDelta Lakeと呼ばれるOpen Table Format(OTF)として保存されます。 ワークスペースで作成したノートブックなども実体はS3に保存されます。
OTFにはそのほかにもApache Icebergなどがありますが、この段階では気にする必要はありませんし、そのうち違いは無くなるので将来的にはそんなこともありましたよねという感じになると思います。
なんだかDatabricks社はOTFをIceberg寄りにしたがってそうな雰囲気をなんとなく感じるので、余裕が出たらIcebergのことも追いかけておくと後々幸せになれるのではないかという気がして来ました。
また、使うのはS3 Tablesのようなものではなく普通のS3です。 Delta Lake自体にバージョニング機能(タイムトラベルクエリ)も持っているため、バケット側のバージョニングも使いません。
計算資源(EC2)
Databricksには主にクラシックコンピュートとサーバレスコンピュートの二種類があります。
そのうち、クラシックコンピュートは顧客のAWSアカウントで動作するEC2を実体としています。 EC2を稼働させるVPCがオンプレミスやほかのAWSリソースに接続しに行ける構成となっていれば、そのままDatabricksからオンプレミスのデータベースに接続することができます。
サーバレスコンピュートはDatabricks社のAWSアカウント上のKubernetesクラスタ上で動作しているらしいです。 そのため、サーバレスコンピュート用の計算資源は管理する必要はありません。
ネットワーク(VPC・Peering・Direct Connect・Site-to-Site VPN)
クラッシックコンピュートの実体がEC2であるならば、そのEC2を稼働させるためのVPCも必要になります。
Databricksからオンプレミスのデータベースに接続する必要があれば、Direct ConnectやSite-to-Site VPNを使用してオンプレミスとの接続性を確保する必要があります。 同様に、他のVPCのリソースに接続しに行く必要があればVPC Peeringなどで接続性を確保する必要があります。
この辺はDatabricks固有のお話というよりかは一般的なVPCネットワークの設計のお話となります。
Databricksコントロールプレーンへの権限の委譲(IAM)
AWSのリソースは顧客のAWSアカウントに作成しますが、クラシックコンピュート起動するたびに手動でEC2インスタンスを作成するわけではありません。
クロスアカウントアクセスが可能なIAMロールをDatabricksに連携しておいて、Databricksの制御側(この制御側をよくコントロールプレーンと呼びます)から必要なEC2インスタンスを作成したり削除してもらいます。
また、S3バケットに格納されているデータにアクセスするためのIAMロールなども作成して連携する必要があります。 クラシックコンピュートやサーバレスコンピュートはこのIAMロールをAssume Roleしてデータに触りに行きます。
Databricks
Databricksではトップレベルの要素として、Unity Catalogとワークスペースが存在します。 Databricksの論理設計ではUnity Catalogとワークスペースの設計を最初に行います。
Unity Catalogの階層構造の設計や、ワークスペースの分割設計が今後のDatabricks運用に多大な影響を与えます。 そのため、この部分の設計はふわっとやらない方が良いと思います。
Unity Catalog
Unity Catalog(UC)はデータを格納しアクセス権を管理するための入れ物となります。
UCはAWSの場合、リージョン毎に1つしか作成することができません。
UCでは常にcatalog.schema.objectという3タプルの識別子でオブジェクト(テーブル・ボリューム・モデル)を識別します。2つにしたり4つにしたりは出来ません。 そのため、カタログやスキーマの階層構造の設計はその後のデータ整理に多大な影響を及ぼします。 また、運用途中での変更には多大な労力がかかります。
ワークスペース
UCがデータの入れ物であるならば、ワークスペースはプログラム(ノートブック・Job・パイプライン・ダッシュボード)と計算資源(クラスタ・AI Search)の入れ物となります。
ワークスペースは一つのリージョンの中に複数することができます。 ワークスペースはアクセスの境界にもなるので、組織間のアクセス制御にワークスペースを使うことも多いです。
クラシックコンピュートとサーバレスコンピュート
クラシックコンピュートとサーバレスコンピュートはワークスペース作成時にどちらを使うか選択するようなものではなく、用途によってそれぞれ使い分けを行います。
サーバレスは制約は多いですが、起動がめっちゃ早いという1点だけでもかなり便利なので、個人的にはサーバレスでは出来ないこと以外は基本的にはサーバレスを使っています。
- クラシックコンピュート
- メリット
- VPCの構成によってはオンプレミスのリソースに接続しに行ける
- EC2のインスタンスタイプやクラスタサイズを柔軟に構成できる
- デメリット
- 起動に時間が掛かる
- メリット
- サーバレスコンピュート
- メリット
- 起動がほぼ一瞬
- デメリット
- サイズはいくつかのサイズから選ぶだけで、細かい調整は出来ない
- (PrivteLinkの設定をしないと)オンプレミスのリソースには接続しに行けないうえに、PrivateLinkは追加のコストが掛かる
- GPUは使えない
- メリット
インフラ設計
ワークスペースとAWSリソースの関係
ワークスペースにはEC2を動かすためのアベイラビリティゾーンが異なるサブネットが最低2つと、ワークスペースのリソースを保存するためのS3バケットが1つ必要になります。
ワークスペースを作成するのに指定したバケットはそのままExternal locationsとしても登録されるので、UCを経由してテーブルなどのUCオブジェクトを保存するのにも使用できます。
また、ワークスペースのバケット以外にも別途バケットを作成してExternal locationとして登録すれば、UCオブジェクトを登録する専用のバケットとして使用することもできます。
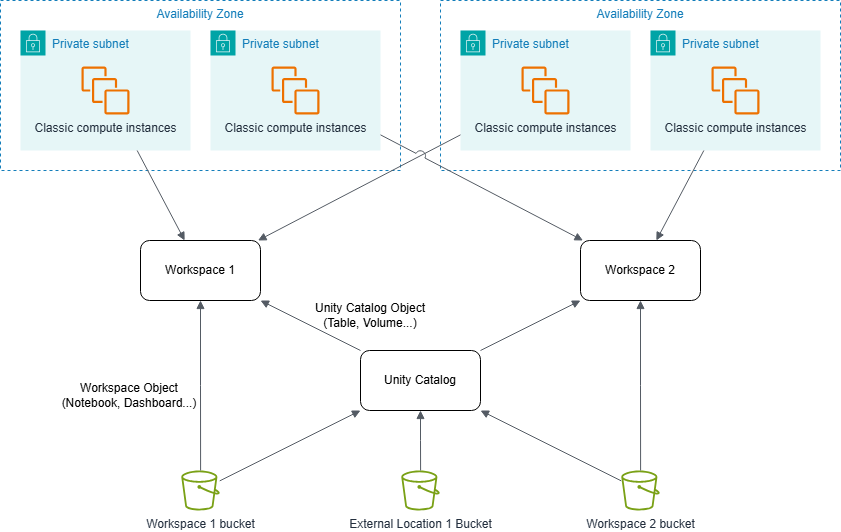
VPC構成
EC2を動かすためのサブネットは最低限インターネットへの接続性があれば大丈夫です。 また、S3用のゲートウェイエンドポイントには費用が掛からないのと、用意しないとS3のアウトバンドコストがまぁまぁ大変なことになるので最低限S3ゲートウェイエンドポイントは用意しておきます。
あとは、オンプレミスのデータベースやほかのVPCへの接続性のためにDirect ConnectやVPC Peeringを必要に応じて設定します。
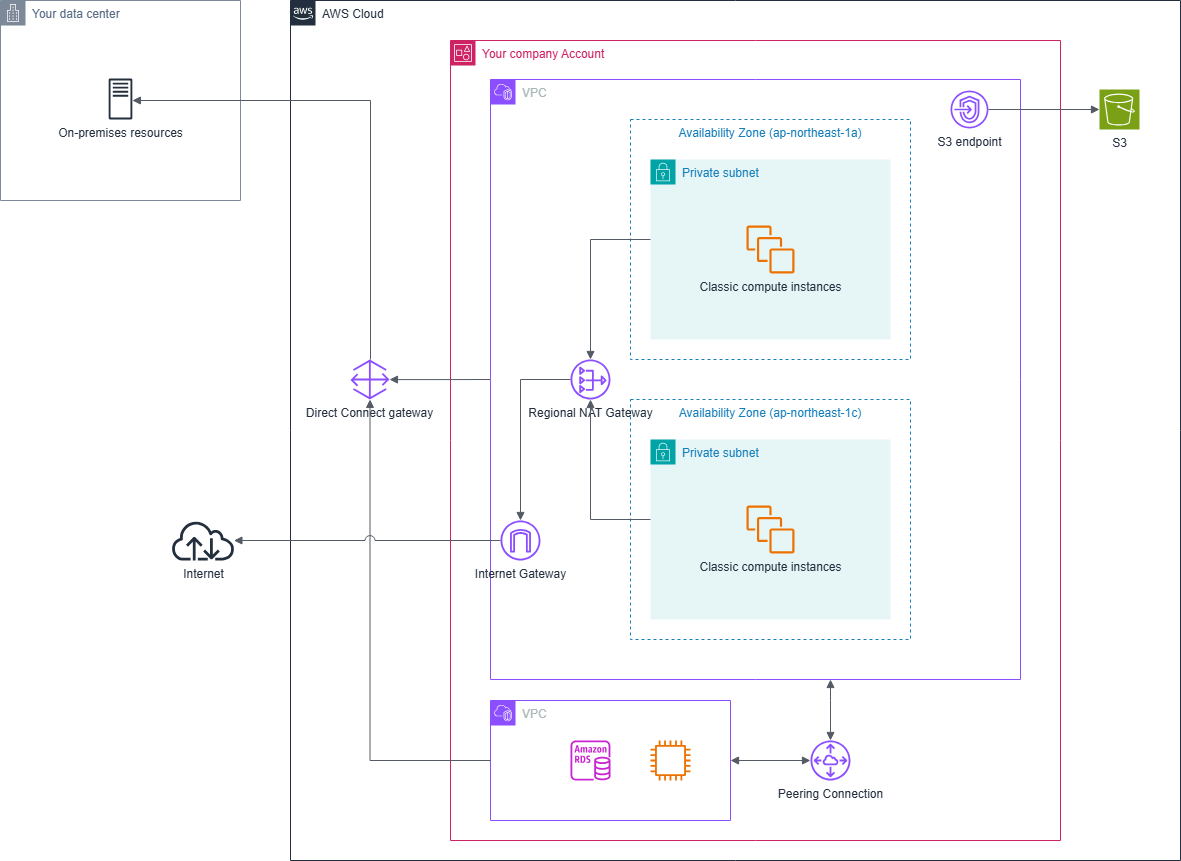
ただし、この構成はクラシックコンピュートとコントロールプレーンの通信はインターネットを経由します。 業界のコンプライアンス要件などでインターネットを経由できない場合、AWSサービスエンドポイントとDatabricksバックエンドサービスへのPrivateLinkを追加で構成することでインターネットへの接続性なしでクラシックコンピュートを運用できます。
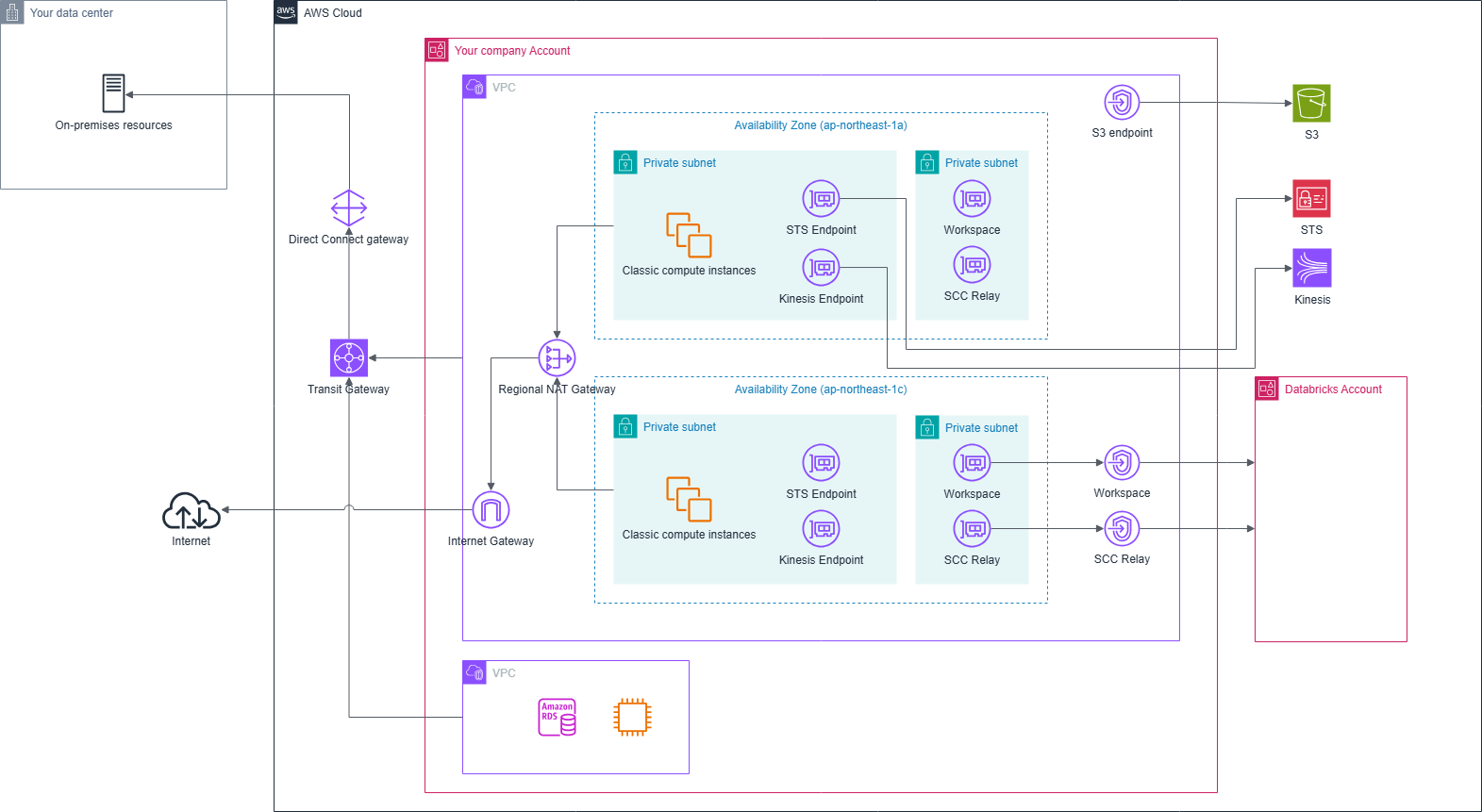
クラシックコンピュートがインターネットへの接続性を持たない構成にすることもできます。 この場合、ノートブックでPythonライブラリをインターネット経由でインストールすることが出来なくなるので、別途プロキシリポジトリを建てるかwheelパッケージをあらかじめダウンロードしてS3などに配置する必要があります。
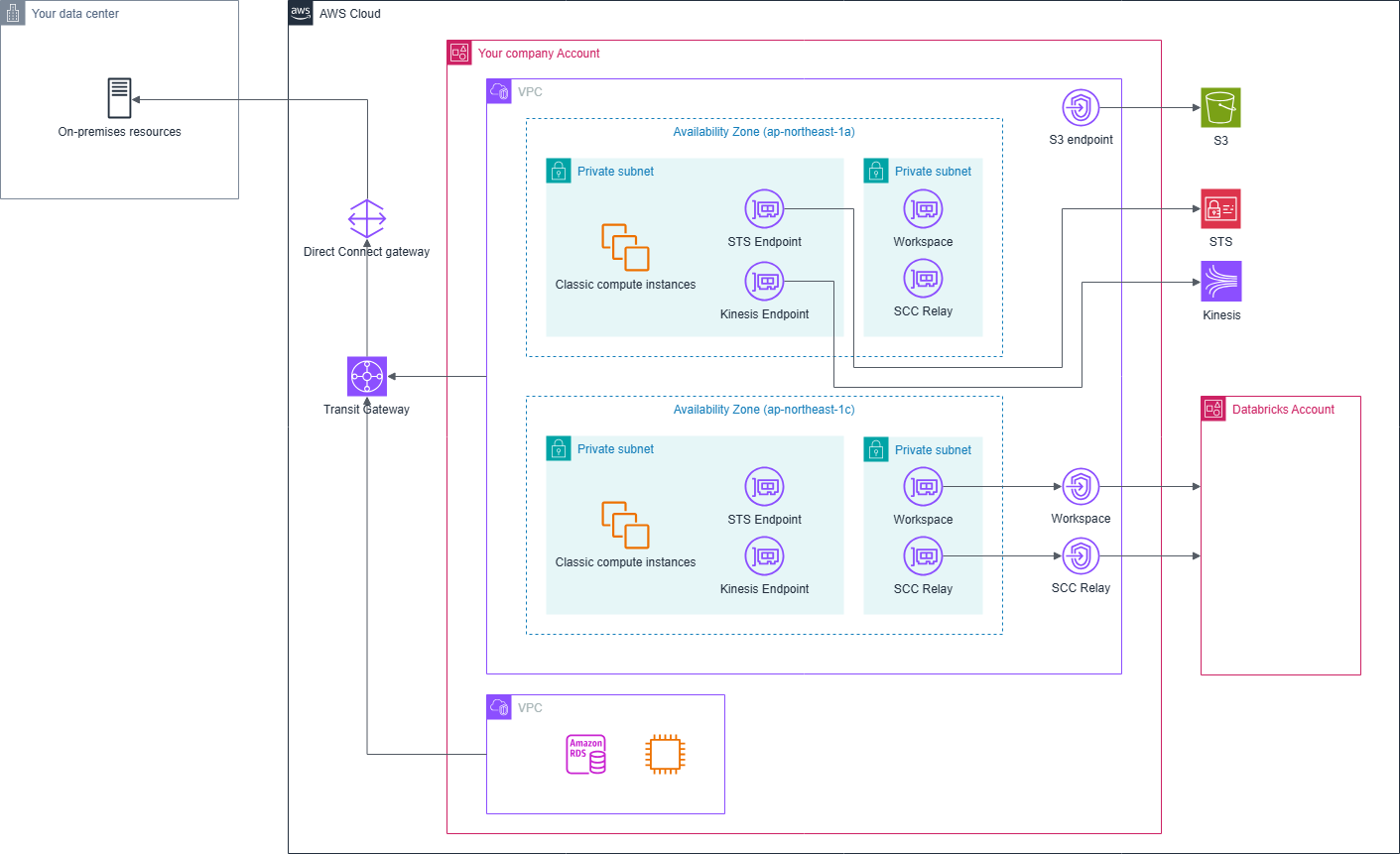
厳密なインターネット分離が求められる場合、クラシックコンピュート⇔コントロールプレーン間だけでなくユーザ⇔コントロールプレーン間でもインターネットを経由しないことが求められるかと思います。 その場合、フロントエンドへの接続もインターネットを経由しない構成にすることができます。
この辺を真面目にやろうとすると結構大変なので、やる場合は実力のあるサポートベンダに相談した方が良いです。
プラクティス
VPCは新規で作成するか?既存のを流用するか?
導入企業の既存のAWS環境の設計やポリシーに強く依存しますが、基本的には分けた方が良いと思います。 VPCが分かれてもVPC PeeringでほかのVPCに触りに行くことが出来ますし、Databricks向けのリソースと他のリソースが混ざる心配もありません。
もっというと、アカウントを分けるぐらいの勢いで行っても良いと思います。
サブネットサイズ設計
クラシックコンピュートのインスタンスは対コントロールプレーンに1つと、クラスタ内の通信に1つの計2つのプライベートアドレスを使用します。 また、クラスタの再起動時や拡張・縮退時など稼働しているインスタンスよりも多い数のプライベートアドレスを使用することがあります。
とはいえ、あるワークスペースに割り当てられたサブネットは他のワークスペースに重複して割り当てが出来ないため、過剰に大きいサブネットに分割してしまうとサブネットが足りなくなる場面も出てきます。私です
個人的には最小のサブネットを/22として、稼働予定のインスタンスの倍の数を収容できるサブネットに分割するのがいいのかなと思っています。
マルチAZ構成
ワークスペースに関連付けるサブネットは最低でも2つ以上のAZで構成しなければいけませんが、高可用構成にするには最低でもNAT Gatewayも1つのAZに1つ作成するなど全体として単一障害点をなくさないといけません。
運用としてはクラシックコンピュートがワークロードの主体になっており、高可用性が求められるのであれば単一障害点をなくす設計を行わないといけません。
対して、普段のワークロードはサーバレスコンピュートが主体でクラシックコンピュートはオンプレミスに触りに行くだけとかであれば費用対効果の観点から高可用を捨ててしまってもいいかもしれません。
リソースの命名規則
DatabricksとAWSという異なる世界のリソースを一緒に扱うため、リソースの命名の一貫性には気を付けています。 過去の経緯から一貫性を欠いているものも一部ありますが、こんな感じで短さよりも分かりやすさを優先して命名をしています。
Databricks
- ワークスペース
{リージョン名}-{連番}apn1-0
AWS
- VPC
databricks-vpc-{リージョン}databricks-vpc-apn1
- サブネット
databricks-subnet-{ワークスペース}-{AZ}databricks-subnet-apn1-0-a
- バケット(カタログ)
databricks-catalog-{リージョン}-rootbucketdatabricks-catalog-apn1-rootbucket
- バケット(ワークスペース)
databricks-workspace-{ワークスペース名}-rootbucketdatabricks-workspace-apn1-0-rootbucket
Terraformでのリソースのデプロイ
どこまでをTerraformなどのIaCに乗せるかは組織や担当者のIaCへの理解度に依存すると思います。
私はAWSのリソースはTerraformでデプロイしていますが、Databricksのリソースは手動で展開しています。
Databricksのリソースはものによっては一度作成したら削除出来ない・一度設定したら削除して再作成しないと変更できないリソースがそこそこあり、無理にTerraform化してよく分からないことになるくらいだったら手動で管理した方が管理しやすいと考えてそのようにしています。
カタログ設計
UCではcatalog.schema.objectの3タプルでオブジェクトが識別されます。 また、アクセス権は階層構造で設定するので、3タプルの構造がそのままアクセス権の構造に影響します。
この辺は組織のポリシーやデータの特性に大きく影響を受けるためこれが正解というのはありませんが、一例として以下のようなイメージが考えられます。
ここではメダリオンアーキテクチャに従って、販売_bronzeをブロンズ層としてデータの着地点として利用します。
後続のシルバー層に向けてデータを供給する役目を持つことからブロンズ層はユーザには見せません。 ブロンズ層は可能な限り上流のシステムに近い構成とし、認知負荷を下げます。
シルバー層ではすべてのユーザが見れる情報と閲覧できる人が限られる情報で分けてカタログに収納します。 閲覧できる人が限られる情報についてはカタログとスキーマで権限を制御します。
| catalog | schema | table |
|---|---|---|
| 販売_bronze | 販売 | 受注 |
| 売上 | ||
| 商品情報 | ||
| CRM | 顧客情報 | |
| 販売 | 販売 | 受注 |
| 売上 | ||
| 商品情報(原価情報なし) | ||
| CRM | 顧客情報(個人情報なし) | |
| 販売_センシティブ | 原価 | 商品情報(原価情報あり) |
| CRM | 顧客情報(個人情報あり) |
ワークスペース設計
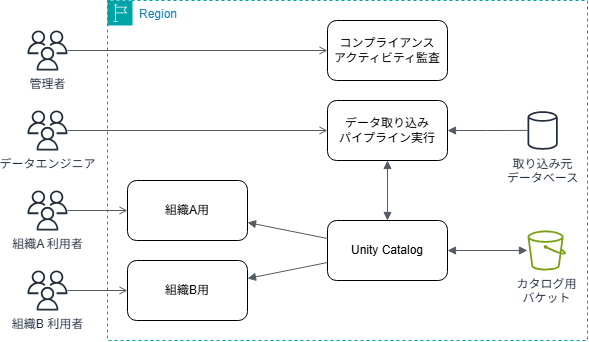
1年近く運用してみて、ワークスペースは以下のように分割するのがいいのかなという感覚を持っています。 まぁ、あくまでも私が所属している組織で都合が良いというだけで、あらゆる組織に適用できるかというと微妙ですが・・・
構成としては、ユーザが触る用のワークスペースとデータエンジニアが作業を行うデータの取り込み・パイプライン実行用のワークスペースを最低限分離します。
これはデータ取り込み用のリソース(ジョブ・パイプライン)と利用者が普段触るリソース(ダッシュボード・Genieスペース)を分離する意図があります。 もちろん、アクセス権を設定すれば触れなくはなりますが、ワークスペースへのアクセス権レベルで制御してしまえば細かいリソース毎のアクセス権は気にしなくてもよくなります。
また、同時に複数のワークスペースからS3上のDeltaテーブルを変更するとデータが壊れるので、データを変更する操作はなるべく単一のワークスペースに寄せるようにしています。
また、ある程度の大きさの組織毎にワークスペースを分離します。 ここでの組織とは、組織図に厳密に対応するものではなく、組織の属性に応じたものを考えています。 組織の属性に応じて、どのカタログをアタッチするかの管理を行い、まずはアタッチするカタログレベルでデータへのアクセス権を絞ります。
もちろん、その先の細かいアクセス権の制御はUnity CatalogなりABACなりで制御を行います。
同様にDatabricks Appsやダッシュボード・Genieスペースはワークスペースに紐づくため、生産部門が営業部門のアプリに触らないまたはその逆が起こらないという観点からもワークスペースを分離します。
あとは、たまにやべー挙動をする利用者が出てくると思うので、その監査用にsystem.auditスキーマのテーブルを使ってアクティビティ監査を行う専用のワークスペースを置いておきます。
カタログ専用バケットのデプロイ
私の組織ではワークスペースとデータを完全に分離したいという考え方からカタログの保存先としてワークスペースのバケットは使用せず、カタログ保存用のバケットを用意したうえでそこに保存しています。
こうしておけばどのカタログがどのバケットに入っているかなどは気にしなくて良くなるので、組織のニーズに応じて柔軟にワークスペースの作成と削除を行えます。
ただし、複数のワークスペースから同じテーブルに変更をかけるとデータが壊れるので、テーブルの更新を行うワークスペースには気を付けた方が良いです。
新機能の検証用にアメリカリージョンにもワークスペースが欲しいよね
Databricksは過去からの傾向として、新機能のPreviewはアメリカのリージョンから利用可能になることが多いです。
私の組織ではアメリカの主要リージョンの中で日本からのレイテンシが比較的小さいus-west-2(オレゴン)に機能の評価用ワークスペースを構築しています。
機能の名前がすごい勢いで変わるので、頑張って追従する
Databricksはなぜかすごい勢いで機能の名前を変更します。
ちょっと思い出すだけでもこのくらいあります。
- AI Search(旧:Vector Search)
- Genie One(旧:Databricks One)
- Spark Declarative Pipelines(旧:Delta Live Table)
- Declarative Automation Bundles(旧:Databricks Asset Bundles)
- OpenSharing(旧:Delta Sharing)
まぁ、ブランディングとか関連機能との整合性とかあるのでしょうがないのかもしれませんが、他の人と機能のことを話す際に「この人はどっちで覚えてるだろうか」みたいな余計な気を遣わないといけないので少し面倒です。
その他参考リファレンス
VPC
Storage
- Create a storage credential and external location for S3 using Catalog Explorer or SQL
- Delta Lake limitations on S3
Workspace
おわり